--------------------[整理]鲲鹏性能优化十板斧系列文章--------------------
| 鲲鹏性能优化十板斧(一)——鲲鹏处理器NUMA简介与性能调优五步法<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(二)——CPU与内存子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(三)——网络子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(四)——磁盘IO子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(五)——应用程序性能调优<TaiShan特战队出品>
---------------------------------------------------------------------------------------------------
1 网络子系统性能调优
1.1 调优简介
调优思路
本章主要是围绕优化网卡性能和利用网卡的能力分担CPU的压力来提升性能。在高并发的业务场景下,推荐使用两块网卡,减少跨片内存访问的次数。即将两块网卡分别绑定在服务器的不同CPU上,每个CPU只处理对应的网卡数据。高并发场景还可以为网卡选择x16的PCIE卡。

高并发场景是指:在同时或极短时间内,有大量的请求到达服务端,每个请求都需要服务端耗费资源进行处理,并做出相应的反馈。
主要优化参数
| 优化项 | 优化项简介 | 默认值 | 生效范围 | 鲲鹏916 | 鲲鹏920 |
| 调整TLP(Transaction Layer Packet)的最大有效负载 | 调整PCIE总线每次数据传输的最大值 | 128B | 重启生效 | Y | Y |
| 设置网卡队列数 | 调整网卡队列数量 | 不同操作系统和网卡不同 | 立即生效 | Y | Y |
| 将每个网卡中断分别绑定到距离最近的核上 | 减少跨NUMA访问内存 | Irqbalance | 立即生效 | Y | Y |
| 聚合中断 | 调整合适的参数以减少中断处理次数 | 不同操作系统和网卡不同 | 立即生效 | Y | Y |
| 开启TCP分段Offload(卸载) | 将TCP的分片处理交给网卡处理 | 关闭 | 立即生效 | Y | Y |
1.2 常用性能监测工具
1.2.1 ethtool工具
介绍
ethtool是一个 Linux 下功能强大的网络管理工具,目前几乎所有的网卡驱动程序都有对 ethtool 的支持,可以用于网卡状态/驱动版本信息查询、收发数据信息查询及能力配置以及网卡工作模式/链路速度等查询配置。
安装方式
以CentOS为例,使用如下命令安装:
# yum -y install ethtool net-tools
使用方式
命令格式:ethtool [参数]
常用参数如下:
| ethX | 查询ethx网口基本设置,其中x是对应网卡的编号,如eth0、eth1等。 |
| -k | 查询网卡的Offload信息。 |
| -K | 修改网卡的Offload信息。 |
| -c | 查询网卡聚合信息。 |
| -C | 修改网卡聚合信息。 |
| -l | 查看网卡队列数。 |
| -L | 设置网卡队列数。 |
输出格式:
# ethtool –k eth0
Features for eth0:
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
tcp-segmentation-offload: on
# ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
…
Current hardware settings:
…
Combined: 8
# ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: off
…
rx-usecs:30
rx-frames:50
…
tx-usecs:30
tx-frames:1
参数含义如下:
| 参数 | 说明 |
| rx-checksumming | 接收包校验和。 |
| tx-checksumming | 发送包校验和。 |
| scatter-gather | 分散-聚集功能,是网卡支持TSO的必要条件之一。 |
| tcp-segmentation-offload | 简称为TSO,利用网卡对TCP数据包分片。 |
| Combined | 网卡队列数。 |
| adaptive-rx | 接收队列的动态聚合执行开关。 |
| adaptive-tx | 发送队列的动态聚合执行开关。 |
| tx-usecs | 产生一个中断之前至少有一个数据包被发送之后的微秒数。 |
| tx-frames | 产生中断之前发送的数据包数量。 |
| rx-usecs | 产生一个中断之前至少有一个数据包被接收之后的微秒数。 |
| rx-frames | 产生中断之前接收的数据包数量。 |
1.2.2 strace工具
介绍
strace是Linux环境下的程序调试工具,用来跟踪应用程序的系统调用情况。strace命令执行的结果就是按照调用顺序打印出所有的系统调用,包括函数名、参数列表以及返回值等。
安装方式
以CentOS为例,使用如下命令安装:
# yum -y install strace
使用方式
命令格式:strace [参数]
常用参数如下:
| -T | 显示每一调用所耗的时间。 |
| -tt | 在输出中的每一行前加上时间信息,微秒级。 |
| -p | 跟踪指定的线程ID。 |
输出格式:
18:25:47.902439 epoll_pwait(716, [{EPOLLIN, {u32=1052576880, u64=281463144385648}}, {EPOLLIN, {u32=1052693569, u64=281463144502337}}, {EPOLLOUT, {u32=1052638657, u64=281463144447425}}, {EPOLLIN|EPOLLOUT|EPOLLRDHUP, {u32=1052673241, u64=281463144482009}}, {EPOLLIN|EPOLLOUT|EPOLLERR|EPOLLHUP|EPOLLRDHUP, {u32=1052636016, u64=281463144444784}}], 512, 1, NULL, 8) = 5 <0.000038>
参数含义如下:
| 参数 | 说明 |
| 18:25:47.902439 | 为系统调用发生的时间。 |
| epoll_pwait | 为系统调用的函数名。 |
| (716…) | 括号内的值为函数参数。 |
| =5 | 为系统调用的返回值。 |
| <0.000038> | 为系统调用的执行时间。 |
1.3 优化方法
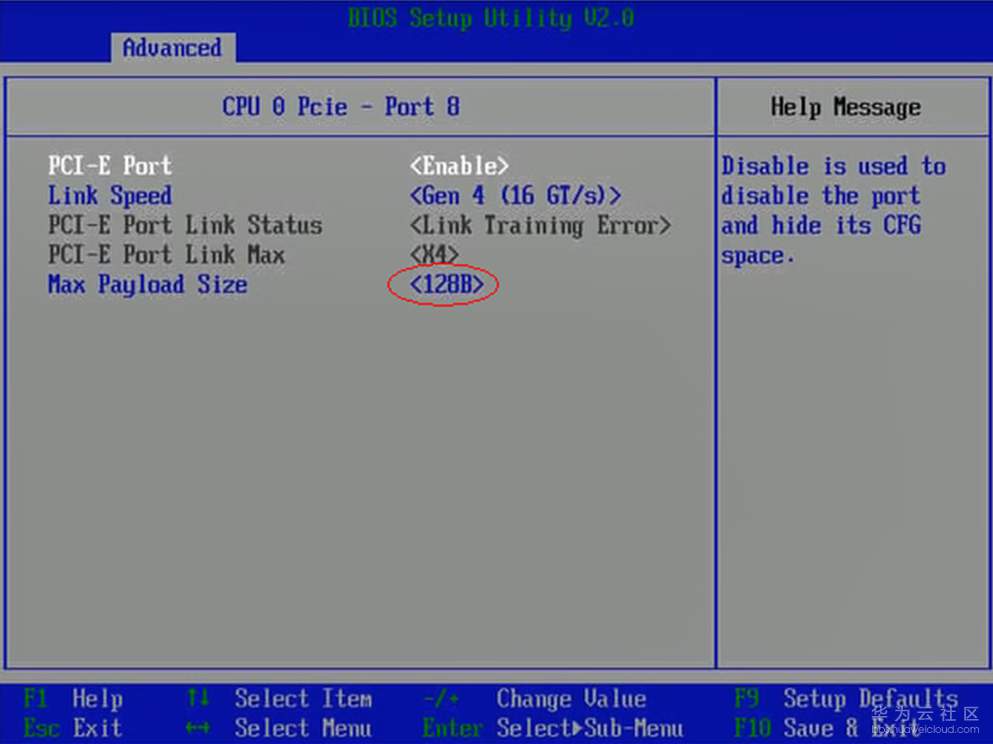
1.3.1 PCIE Max Payload Size大小配置
原理
网卡自带的内存和CPU使用的内存进行数据传递时,是通过PCIE总线进行数据搬运的。Max Payload Size为每次传输数据的最大单位(以字节为单位),它的大小与PCIE链路的传送效率成正比,该参数越大,PCIE链路带宽的利用率越高。
| Transaction Layer Packet | ||
| Header | Data Payload | ECRC |
修改方式
按照B 进入BIOS界面的步骤进入BIOS,选择“Advanced > Max Payload Size”,将“Max Payload Size”的值设置为“512B”。
1.3.2 网络NUMA绑核
原理
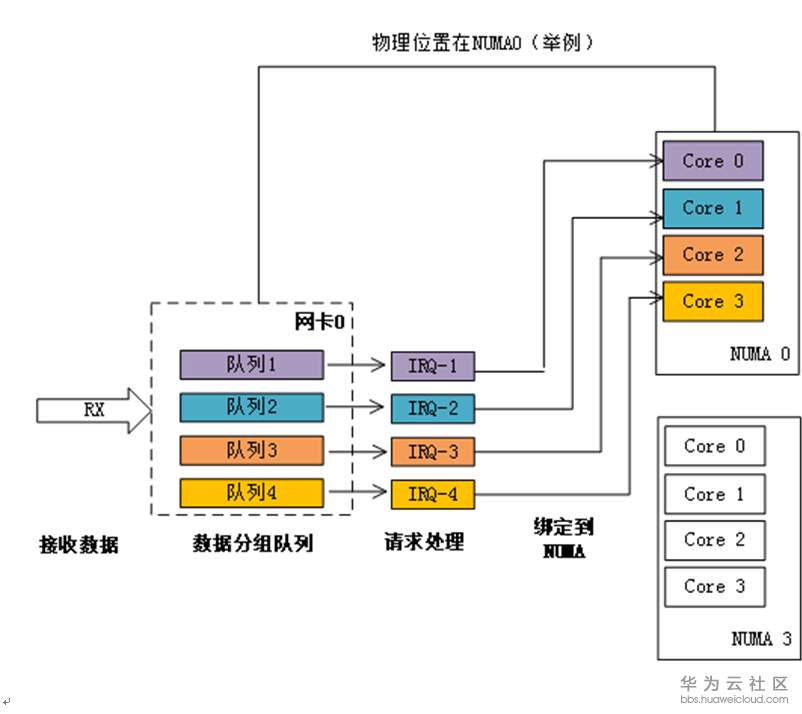
当网卡收到大量请求时,会产生大量的中断,通知内核有新的数据包,然后内核调用中断处理程序响应,把数据包从网卡拷贝到内存。当网卡只存在一个队列时,同一时间数据包的拷贝只能由某一个core处理,无法发挥多核优势,因此引入了网卡多队列机制,这样同一时间不同core可以分别从不同网卡队列中取数据包。
在网卡开启多队列时,操作系统通过Irqbalance服务来确定网卡队列中的网络数据包交由哪个CPU core处理,但是当处理中断的CPU core和网卡不在一个NUMA时,会触发跨NUMA访问内存。因此,我们可以将处理网卡中断的CPU core设置在网卡所在的NUMA上,从而减少跨NUMA的内存访问所带来的额外开销,提升网络处理性能。
图1-1 自动绑定:中断绑定随机,出现跨NUMA访问内存
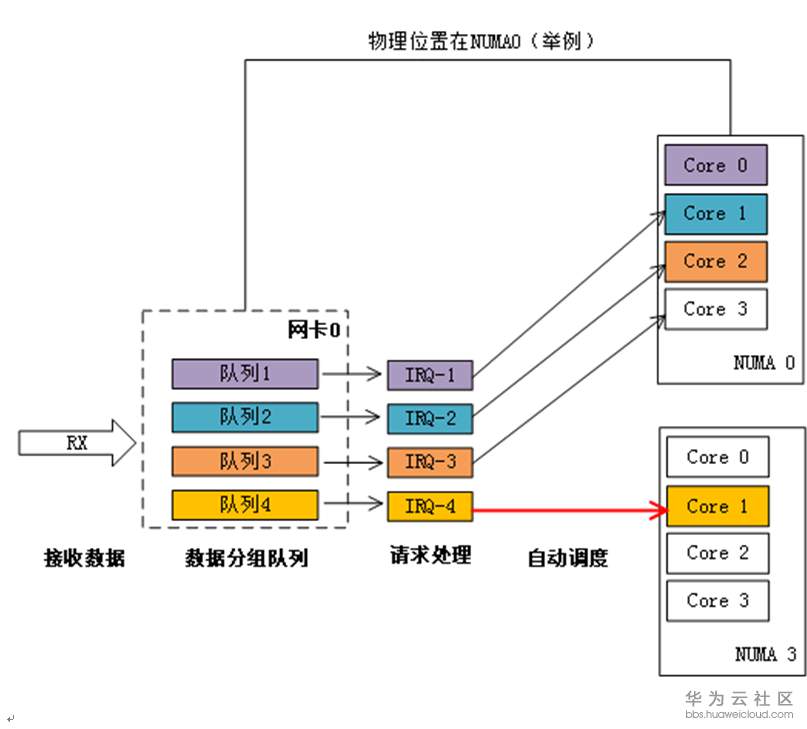
图1-2 NUMA绑定:中断绑定到指定核,避免跨NUMA访问内存
修改方式
步骤 1 停止irqbalance。
# systemctl stop irqbalance.service
# systemctl disable irqbalance.service
步骤 2 设置网卡队列个数为CPU的核数。
# ethtool -L ethx combined 48
步骤 3 查询中断号。
# cat /proc/interrupts | grep $eth | awk -F ':' '{print $1}'
步骤 4 根据中断号,将每个中断分别绑定在一个核上,其中cpuMask是16进制的数,最右边的bit表示core0。
# echo $cpuMask > /proc/irq/$irq/smp_affinity_list
----结束
1.3.3 中断聚合参数调整
原理
中断聚合特性允许网卡收到报文之后不立即产生中断,而是等待一小段时间有更多的报文到达之后再产生中断,这样就能让CPU一次中断处理多个报文,减少开销。
修改方式
使用ethtool -C $eth方法调整中断聚合参数。其中参数“$eth”为待调整配置的网卡设备名称,如eth0,eth1等。
# ethtool -C eth3 adaptive-rx off adaptive-tx off rx-usecs N rx-frames N tx-usecs N tx-frames N
为了确保使用静态值,需禁用自适应调节,关闭Adaptive RX和Adaptive TX。
l rx-usecs:设置接收中断延时的时间。
l tx-usecs:设置发送中断延时的时间。
l rx-frames:产生中断之前接收的数据包数量。
l tx-frames:产生中断之前发送的数据包数量。
这4个参数设置N的数值越大,中断越少。

增大聚合度,单个数据包的延时会有微秒级别的增加。
1.3.4 开启TSO
原理
当一个系统需要通过网络发送一大段数据时,计算机需要将这段数据拆分为多个长度较短的数据,以便这些数据能够通过网络中所有的网络设备,这个过程被称作分段。TCP分段卸载将TCP的分片运算(如将要发送的1M字节的数据拆分为MTU大小的包)交给网卡处理,无需协议栈参与,从而降低CPU的计算量和中断频率。
修改方式
使用ethtool工具打开网卡和驱动对TSO(TCP Segmentation Offload)的支持。如下命令中的参数“$eth”为待调整配置的网卡设备名称,如eth0,eth1等。
# ethtool -K $eth tso on
要使用TSO功能,物理网卡需同时支持TCP校验计算和分散-聚集 (Scatter Gather) 功能。
查看网卡是否支持TSO:
# ethtool -K $eth
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
tcp-segmentation-offload: on
1.3.5 使用epoll代替select
原理
epoll机制是Linux内核中的一种可扩展IO事件处理机制,可被用于代替POSIX select系统调用,在高并发场景下获得较好的性能提升。
select有如下缺点:
l 内核默认最多支持1024个文件句柄
l select采用轮询的方式扫描文件句柄,性能差
epoll改进后的机制:
l 没有最大并发连接的限制,能打开的文件句柄上限远大于1024,方便在一个线程里面处理更多请求
l 采用事件通知的方式,减少了轮询的开销
修改方式
使用epoll函数代替select,epoll函数有:epoll_create,epoll_ctl和epoll_wait。Linux-2.6.19又引入了可以屏蔽指定信号的epoll_wait: epoll_pwait。
函数简介:
步骤 1 创建一个epoll句柄。
int epoll_create(int size);
其中size表示监听的文件句柄的最大个数。
步骤 2 注册要监听的事件类型。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
参数说明如下:
l epfd:epoll_create返回的文件句柄。
l op:要进行的操作,有EPOLL_CTL_ADD、EPOLL_CTL_MOD 、EPOLL_CTL_DEL等。
l fd:要操作的文件句柄。
l event:事件描述,常用的事件有:
− EPOLLIN:文件描述符上有可读数据。
− EPOLLOUT:文件描述符上可以写数据。
− EPOLLERR: 表示对应的文件描述符发生错误。
步骤 3 等待事件的产生。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
int epoll_pwait(int epfd, struct epoll_event *events,
int maxevents, int timeout,
const sigset_t *sigmask);
参数说明如下:
l epfd:epoll_create返回的文件句柄。
l events:返回待处理事件的数组。
l maxevents:events数组长度。
l timeout:超时时间,单位为毫秒。
l sigmask:屏蔽的信号。
----结束
在网络高并发场景下,select调用可使用epoll进行替换。
使用如下命令确认是否调用epoll函数:
查看某个进程的系统调用信息
# strace -p $TID -T –tt
18:25:47.902439 epoll_pwait(716, [{EPOLLIN, {u32=1052576880, u64=281463144385648}}, {EPOLLIN, {u32=1052693569, u64=281463144502337}}, {EPOLLOUT, {u32=1052638657, u64=281463144447425}}, {EPOLLIN|EPOLLOUT|EPOLLRDHUP, {u32=1052673241, u64=281463144482009}}, {EPOLLIN|EPOLLOUT|EPOLLERR|EPOLLHUP|EPOLLRDHUP, {u32=1052636016, u64=281463144444784}}], 512, 1, NULL, 8) = 5 <0.000038>
=====结束分隔符=====
上述文章转载自华为云社区:
【1024程序员节献礼】鲲鹏性能优化十板斧(三)——网络子系统性能调优<TaiShan特战队出品>
转载仅供学习,如有侵权,请第一时间告知,本站第一时间删除。
站长邮箱:MzQ1MTYxOTc0QHFxLmNvbQ==
文章的脚注信息由WordPress的wp-posturl插件自动生成

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~![[整理]鲲鹏性能优化十板斧(五)——应用程序性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/03/1-4.jpg&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(四)——磁盘IO子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=https://bbs-img.huaweicloud.com/blogs/img/1572357064241058.png&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(二)——CPU与内存子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/03/1.jpg&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(一)——鲲鹏处理器NUMA简介与性能调优五步法<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/03/1-1.jpg&w=280&h=210&zc=1)