这篇博客只是为了引出Linux下epoll编程,其实本博客之前就有过Linux下socket编程的相关系列教程,如下:
【整理】Linux Socket网络编程_TCP编程(1)_基础版本
【整理】Linux Socket网络编程_TCP编程(2)_多进程版本
【整理】Linux Socket网络编程_TCP编程(3)_多线程版本
【整理】Linux Socket网络编程_TCP编程(4)_C++与PythonSocket通信
我们的需求是,每有一个客户端连接上来,便创建一个单独的通信进程进行通信。
Server端的代码:
#include <unistd.h>
#include <sys/types.h> /* basic system data types */
#include <sys/socket.h> /* basic socket definitions */
#include <netinet/in.h> /* sockaddr_in{} and other Internet defns */
#include <arpa/inet.h> /* inet(3) functions */
#include <stdlib.h>
#include <errno.h>
#include <stdio.h>
#include <string.h>
#define MAXLINE 1024
//typedef struct sockaddr SA;
void handle(int connfd);
int main(int argc, char **argv)
{
int listenfd, connfd;
int serverPort = 6888;
int listenq = 1024;
pid_t childpid;
char buf[MAXLINE];
socklen_t socklen;
struct sockaddr_in cliaddr, servaddr;
socklen = sizeof(cliaddr);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(serverPort);
listenfd = socket(AF_INET, SOCK_STREAM, 0);
if (listenfd < 0) {
perror("socket error");
return -1;
}
if (bind(listenfd, (struct sockaddr *) &servaddr, socklen) < 0) {
perror("bind error");
return -1;
}
if (listen(listenfd, listenq) < 0) {
perror("listen error");
return -1;
}
printf("echo server startup,listen on port:%d\n", serverPort);
for ( ; ; ) {
connfd = accept(listenfd, (struct sockaddr *)&cliaddr, &socklen);
if (connfd < 0) {
perror("accept error");
continue;
}
sprintf(buf, "accept form %s:%d\n", inet_ntoa(cliaddr.sin_addr), cliaddr.sin_port);
printf(buf,"");
childpid = fork();
if (childpid == 0) { /* child process */
close(listenfd); /* close listening socket */
handle(connfd); /* process the request */
exit (0);
} else if (childpid > 0) {
close(connfd); /* parent closes connected socket */
} else {
perror("fork error");
}
}
}
void handle(int connfd)
{
size_t n;
char buf[MAXLINE];
for(;;) {
n = read(connfd, buf, MAXLINE);
if (n < 0) {
if(errno != EINTR) {
perror("read error");
break;
}
}
if (n == 0) {
//connfd is closed by client
close(connfd);
printf("client exit\n");
break;
}
//client exit
if (strncmp("exit", buf, 4) == 0) {
close(connfd);
printf("client exit\n");
break;
}
write(connfd, buf, n); //write maybe fail,here don't process failed error
}
}
Client端的代码:
#include <unistd.h>
#include <sys/types.h> /* basic system data types */
#include <sys/socket.h> /* basic socket definitions */
#include <netinet/in.h> /* sockaddr_in{} and other Internet defns */
#include <arpa/inet.h> /* inet(3) functions */
#include <netdb.h> /*gethostbyname function */
#include <stdlib.h>
#include <errno.h>
#include <stdio.h>
#include <string.h>
#define MAXLINE 1024
void handle(int connfd);
int main(int argc, char **argv)
{
char * servInetAddr = "127.0.0.1";
int servPort = 6888;
char buf[MAXLINE];
int connfd;
struct sockaddr_in servaddr;
if (argc == 2) {
servInetAddr = argv[1];
}
if (argc == 3) {
servInetAddr = argv[1];
servPort = atoi(argv[2]);
}
if (argc > 3) {
printf("usage: echoclient <IPaddress> <Port>\n");
return -1;
}
connfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(servPort);
inet_pton(AF_INET, servInetAddr, &servaddr.sin_addr);
if (connect(connfd, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0) {
perror("connect error");
return -1;
}
printf("welcome to echoclient\n");
handle(connfd); /* do it all */
close(connfd);
printf("exit\n");
exit(0);
}
void handle(int sockfd)
{
char sendline[MAXLINE], recvline[MAXLINE];
int n;
for (;;) {
if (fgets(sendline, MAXLINE, stdin) == NULL) {
break;//read eof
}
/*
//也可以不用标准库的缓冲流,直接使用系统函数无缓存操作
if (read(STDIN_FILENO, sendline, MAXLINE) == 0) {
break;//read eof
}
*/
n = write(sockfd, sendline, strlen(sendline));
n = read(sockfd, recvline, MAXLINE);
if (n == 0) {
printf("echoclient: server terminated prematurely\n");
break;
}
write(STDOUT_FILENO, recvline, n);
//如果用标准库的缓存流输出有时会出现问题
//fputs(recvline, stdout);
}
}
演示效果:
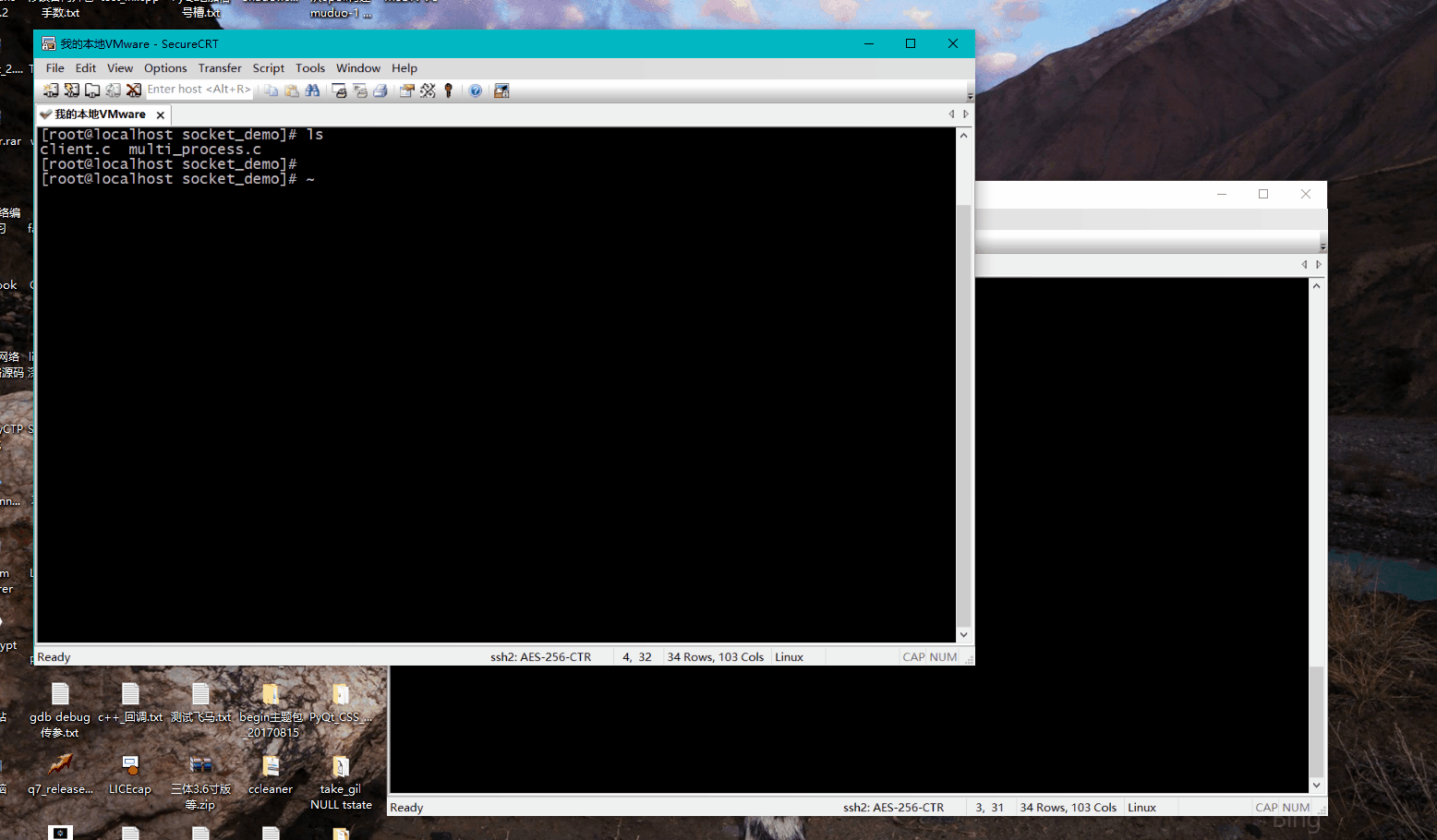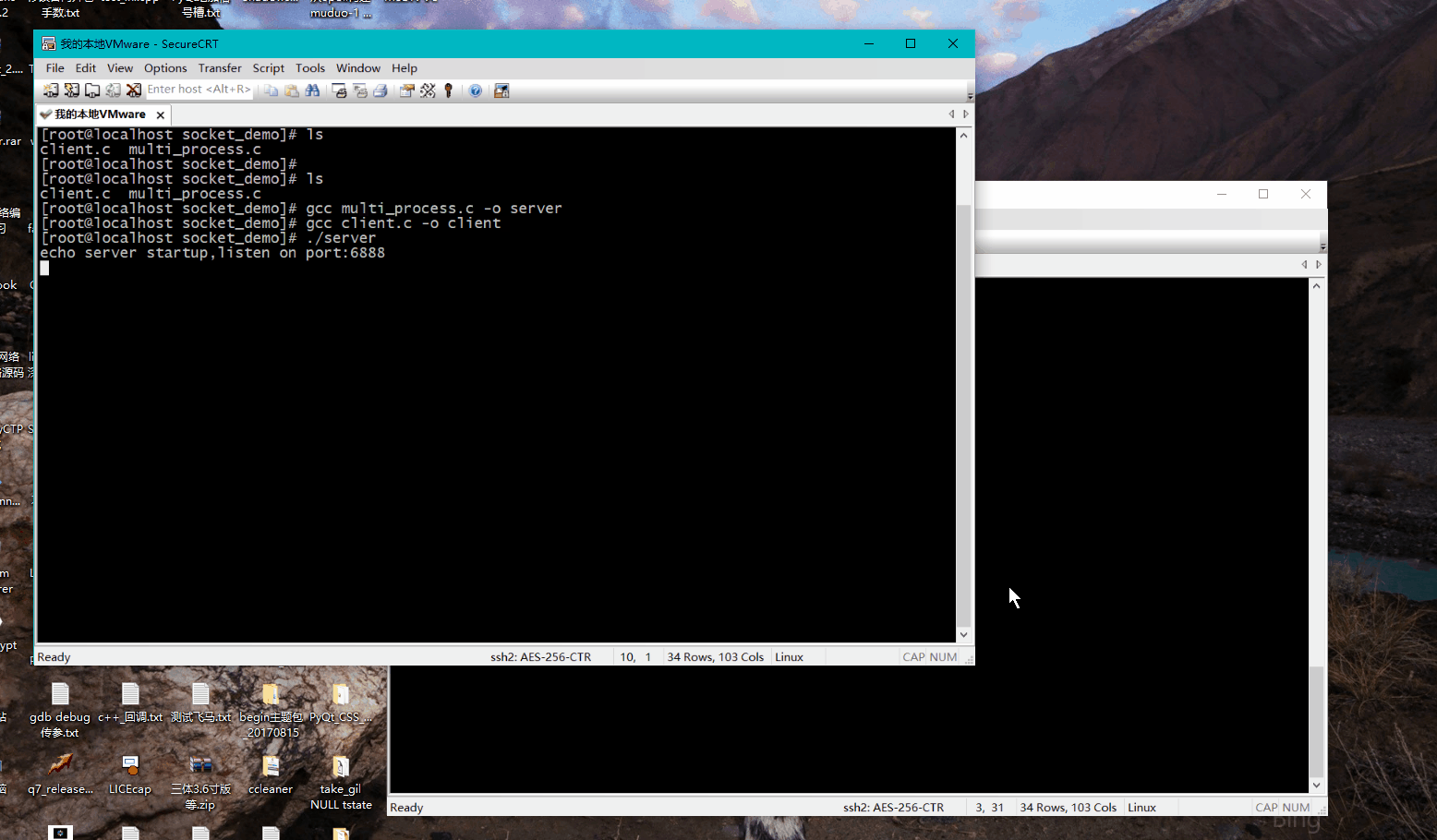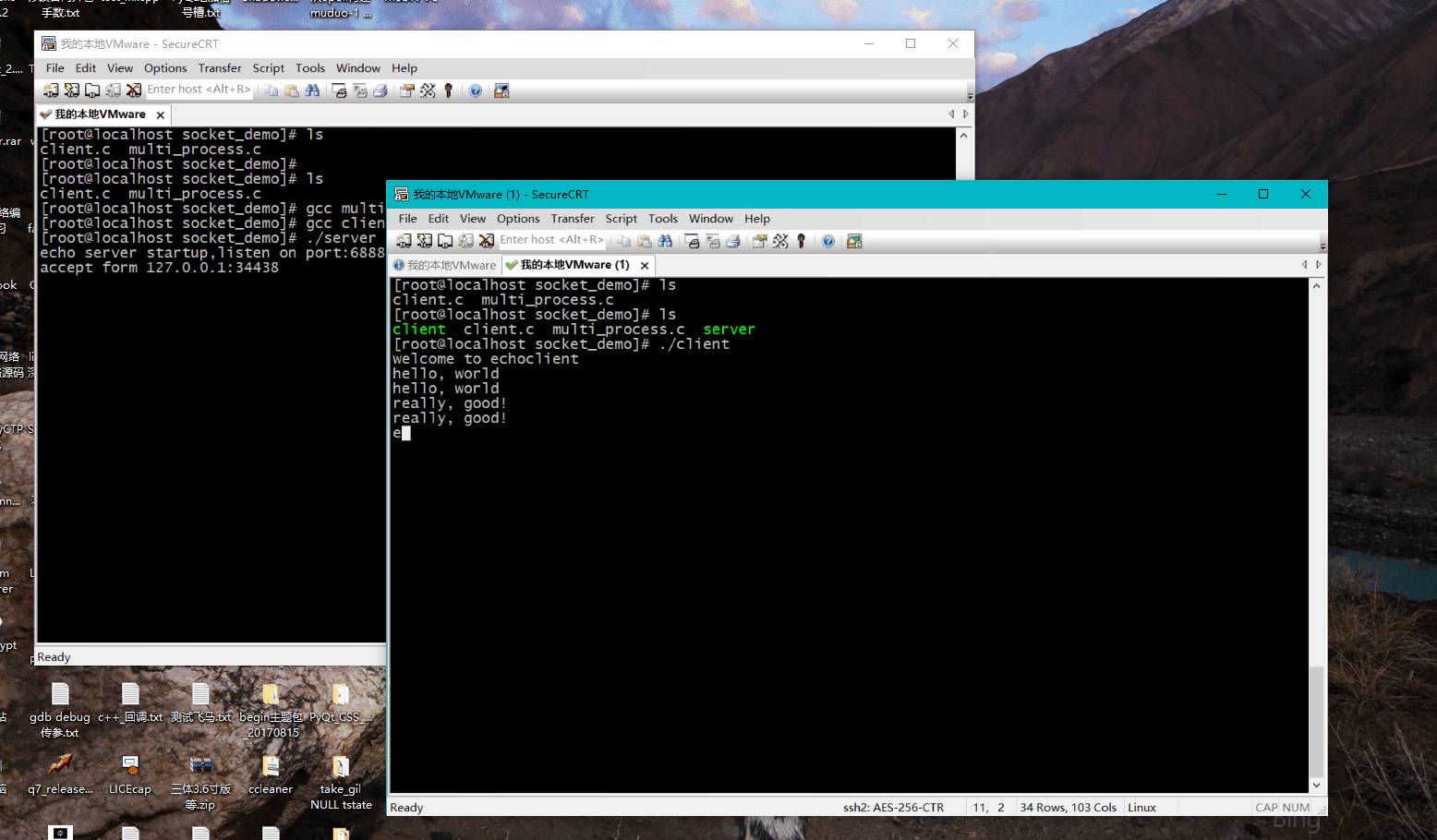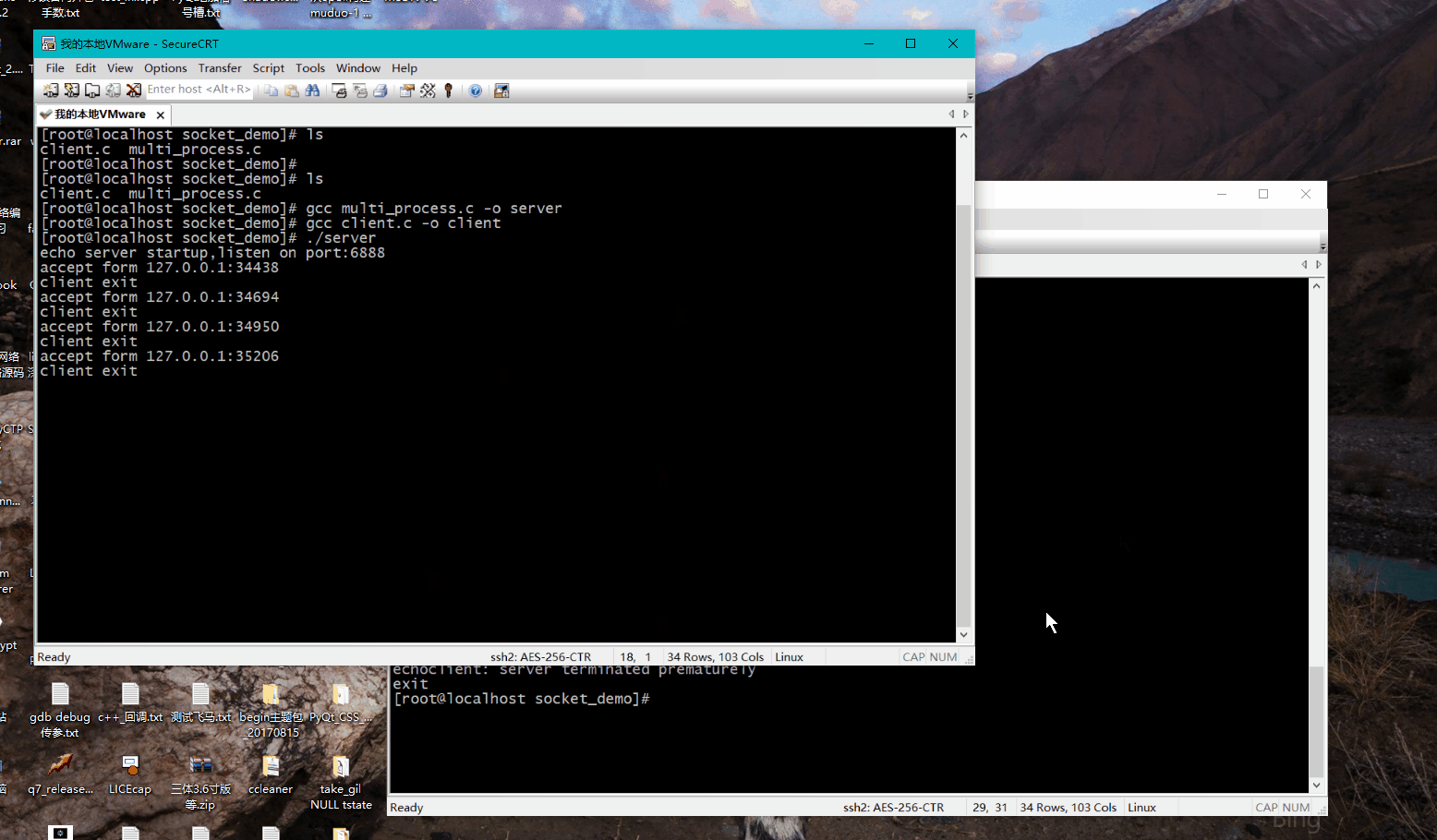
我们建立多次会话之后,发现每次建立一次连接,便会创建一个进程:
假如会话数量是100,那么就有100个进程,如果是成千上万呢?这种方式从性能上分析显然不行,每个进程占据的内存,cpu资源都是比较大的。虽然这个是多进程版本,其实换成多线程版本,也一样存在这种瓶颈,当建立的连接达到成千上万后,这种多线程、多进程版本的socket通信就不能满足高性能的需求了。进程的开销,线程的切换,都是性能开销。
那么我们应该采取什么样的方式进行性能提升呢?
这里我们就需要Linux下的epoll编程了,那么什么是epoll呢?可以参考知乎上某大神的回答:
链接:https://www.zhihu.com/question/20122137/answer/14049112
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不管是文件,还是套接字,还是管道,我们都可以把他们看作流。
之后我们来讨论I/O的操作,通过read,我们可以从流中读入数据;通过write,我们可以往流写入数据。现在假定一个情形,我们需要从流中读数据,但是流中还没有数据,(典型的例子为,客户端要从socket读如数据,但是服务器还没有把数据传回来),这时候该怎么办?
- 阻塞。阻塞是个什么概念呢?比如某个时候你在等快递,但是你不知道快递什么时候过来,而且你没有别的事可以干(或者说接下来的事要等快递来了才能做);那么你可以去睡觉了,因为你知道快递把货送来时一定会给你打个电话(假定一定能叫醒你)。
- 非阻塞忙轮询。接着上面等快递的例子,如果用忙轮询的方法,那么你需要知道快递员的手机号,然后每分钟给他挂个电话:“你到了没?”
很明显一般人不会用第二种做法,不仅显很无脑,浪费话费不说,还占用了快递员大量的时间。
大部分程序也不会用第二种做法,因为第一种方法经济而简单,经济是指消耗很少的CPU时间,如果线程睡眠了,就掉出了系统的调度队列,暂时不会去瓜分CPU宝贵的时间片了。
为了了解阻塞是如何进行的,我们来讨论缓冲区,以及内核缓冲区,最终把I/O事件解释清楚。缓冲区的引入是为了减少频繁I/O操作而引起频繁的系统调用(你知道它很慢的),当你操作一个流时,更多的是以缓冲区为单位进行操作,这是相对于用户空间而言。对于内核来说,也需要缓冲区。
假设有一个管道,进程A为管道的写入方,B为管道的读出方。
- 假设一开始内核缓冲区是空的,B作为读出方,被阻塞着。然后首先A往管道写入,这时候内核缓冲区由空的状态变到非空状态,内核就会产生一个事件告诉B该醒来了,这个事件姑且称之为“缓冲区非空”。
- 但是“缓冲区非空”事件通知B后,B却还没有读出数据;且内核许诺了不能把写入管道中的数据丢掉这个时候,A写入的数据会滞留在内核缓冲区中,如果内核也缓冲区满了,B仍未开始读数据,最终内核缓冲区会被填满,这个时候会产生一个I/O事件,告诉进程A,你该等等(阻塞)了,我们把这个事件定义为“缓冲区满”。
- 假设后来B终于开始读数据了,于是内核的缓冲区空了出来,这时候内核会告诉A,内核缓冲区有空位了,你可以从长眠中醒来了,继续写数据了,我们把这个事件叫做“缓冲区非满”
- 也许事件Y1已经通知了A,但是A也没有数据写入了,而B继续读出数据,知道内核缓冲区空了。这个时候内核就告诉B,你需要阻塞了!,我们把这个时间定为“缓冲区空”。
这四个情形涵盖了四个I/O事件,缓冲区满,缓冲区空,缓冲区非空,缓冲区非满(注都是说的内核缓冲区,且这四个术语都是我生造的,仅为解释其原理而造)。这四个I/O事件是进行阻塞同步的根本。(如果不能理解“同步”是什么概念,请学习操作系统的锁,信号量,条件变量等任务同步方面的相关知识)。
然后我们来说说阻塞I/O的缺点。但是阻塞I/O模式下,一个线程只能处理一个流的I/O事件。如果想要同时处理多个流,要么多进程(fork),要么多线程(pthread_create),很不幸这两种方法效率都不高。
于是再来考虑非阻塞忙轮询的I/O方式,我们发现我们可以同时处理多个流了(把一个流从阻塞模式切换到非阻塞模式再此不予讨论):
while true {
for i in stream[]; {
if i has data
read until unavailable
}
}
我们只要不停的把所有流从头到尾问一遍,又从头开始。这样就可以处理多个流了,但这样的做法显然不好,因为如果所有的流都没有数据,那么只会白白浪费CPU。这里要补充一点,阻塞模式下,内核对于I/O事件的处理是阻塞或者唤醒,而非阻塞模式下则把I/O事件交给其他对象(后文介绍的select以及epoll)处理甚至直接忽略。
为了避免CPU空转,可以引进了一个代理(一开始有一位叫做select的代理,后来又有一位叫做poll的代理,不过两者的本质是一样的)。这个代理比较厉害,可以同时观察许多流的I/O事件,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中醒来,于是我们的程序就会轮询一遍所有的流(于是我们可以把“忙”字去掉了)。代码长这样:
while true {
select(streams[])
for i in streams[] {
if i has data
read until unavailable
}
}
于是,如果没有I/O事件产生,我们的程序就会阻塞在select处。但是依然有个问题,我们从select那里仅仅知道了,有I/O事件发生了,但却并不知道是那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。
但是使用select,我们有O(n)的无差别轮询复杂度,同时处理的流越多,每一次无差别轮询时间就越长。再次
说了这么多,终于能好好解释epoll了
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll之会把哪个流发生了怎样的I/O事件通知我们。此时我们对这些流的操作都是有意义的。(复杂度降低到了O(k),k为产生I/O事件的流的个数,也有认为O(1)的[更新 1])
在讨论epoll的实现细节之前,先把epoll的相关操作列出[更新 2]:
- epoll_create 创建一个epoll对象,一般epollfd = epoll_create()
- epoll_ctl (epoll_add/epoll_del的合体),往epoll对象中增加/删除某一个流的某一个事件
比如
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);//有缓冲区内有数据时epoll_wait返回
epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT);//缓冲区可写入时epoll_wait返回 - epoll_wait(epollfd,...)等待直到注册的事件发生
(注:当对一个非阻塞流的读写发生缓冲区满或缓冲区空,write/read会返回-1,并设置errno=EAGAIN。而epoll只关心缓冲区非满和缓冲区非空事件)。
一个epoll模式的代码大概的样子是:
while true {
active_stream[] = epoll_wait(epollfd)
for i in active_stream[] {
read or write till unavailable
}
}
限于篇幅,我只说这么多,以揭示原理性的东西,至于epoll的使用细节,请参考man和google,实现细节,请参阅linux kernel source。
======================================
[更新1]: 原文为O(1),但实际上O(k)更为准确
[更新2]: 原文所列第二点说法让人产生EPOLLIN/EPOLLOUT等同于“缓冲区非空”和“缓冲区非满”的事件,但并非如此,详细可以Google关于epoll的边缘触发和水平触发。
说来说去,epoll是Linux 内核层面上支持的一种技术,性能出众。更多了解可以参考:
综上,为了支持更高性能级别的socket server,我们需要将我们的代码改为epoll。在下一文中,我们将把代码改为epoll模式代码。
文章的脚注信息由WordPress的wp-posturl插件自动生成

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~![[整理][转载]win下网卡抓包发包库Npcap使用](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2023/08/demo_1-1024x711.jpg&w=280&h=210&zc=1)
![[转载]基础数据char,int,double,string是线程安全的吗?](http://www.jyguagua.com/wp-content/themes/begin/img/random/9.jpg)
![[已解决]nc命令报错 close: Bad file descriptor](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2022/03/Snipaste_2022-03-18_20-16-48.png&w=280&h=210&zc=1)
![[整理]用c++编写的RDTSC性能计时器](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/12/rdtsc-assembly-example.jpg&w=280&h=210&zc=1)